鋳造ならば、製品マスターと製造実績や不良発生をリンクして、単重x生産数=重量 の項目を作り、それを集計することで、特定品の生産量や不良重量を出すこともデータベースソフトの機能を使えば簡単です。
品質管理では、不良内容をまとめたエクセルファイルは、膨大な件数になるので分析・分類・集計は大変ですが、エクセルをAccessにリンクしたり、polarsやpandasやデータベースソフトに取り込めると、それぞれの便利な機能を使え、容易に分析・分類・解析ができるようになります。
データベースシステムを作るのはプロの仕事ですが、システムにあるデータを利用するのは意外と簡単です。
データベースから出てくるのは表形式のデータ。代表はエクセルやCSVファイルの形式です。
MicrosoftのデータベースソフトAccessは、エクセルファイルにリンクでき検索プログラム(クエリー)が項目ドラッグするマウス操作で自動生成。
Excelの分析(項目抽出・行抽出・マスタ連携)がAccessから使え、プログラムの作成効率は抜群で、一度作るといつでも再利用できる。
データベースに慣れる、使い方を学ぶにも使えます。
作成したクエリーは他のデータベースと共通で利用できます。Updateされると過去のものが使えなくなることも。
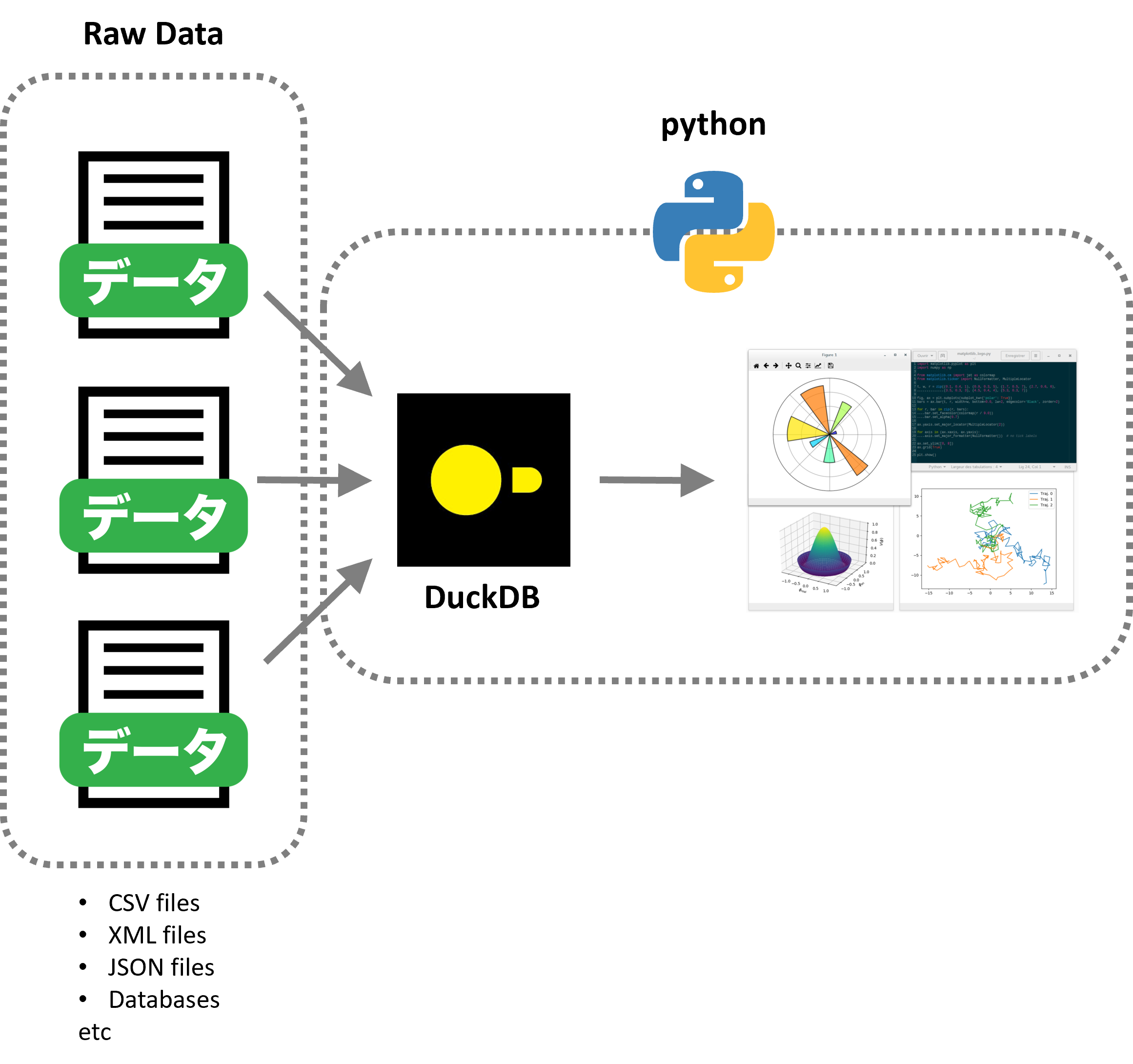
一方で、最近続々と出てきた高性能フリーソフト(無料)の表形式活用・分析ソフトのpolarsや、高性能データベースduckdbをご紹介。
やり方は、
エクセルを無料で使える表形式ソフト PandasやPolarsやDuckdbに読み込み、無料で利用できる高性能DBソフトの duckdb と連携させるとDB機能のSQLのクエリが使えます。
1.python, polars pandas duckdb をパソコンにインストール
(1) python、duckdbをインストール
(2)コマンドプロンプトで、下記をpythonが使えるようにインストールする
py -m pip install polars
py -m pip install pandas
py -m pip install duckdb
2.分析したいエクセルやcsvファイルを準備
3.python の統合開発環境の IDLE でpython 立ち上げ、プログラムにimportする。
import polars as pl
import duckdb
4.polars で分析したいエクセルやcsvファイルを読み込む。
※polarsの読み込み不安定な場合は読み込み行数制限を解除、duckdbの read_csv()も利用できる。
duckdbで、polars で読み込んだDataFrameをテーブルと見なしてSQLクエリーを実行し、その結果を表示したり、polarsのDataFrameに取りこむ。結果をプリントしたり、できたファイルをさらに再利用する。
duckdbをcsvの読み込み装置として、その結果をpolarsに渡すことも可能。
polarsは扱いやすく高速なので、データを取り込めれば簡単な手順でクエリー相当ができ、またクエリーも利用できる。
duckdbは、データベースを作成して外部のファイルをtableとして読み込んいく通常のデータベース手順があるが、
それ以外に外部のエクセルやCSVファイルやデータベースに接続し、データベースの機能を使うこともできる。
下記では、後者の方法例として、polarsで外部のエクセルを読み込み、polarsのDataFrameをduckdbのtableとして利用し、そのデータベースのクエリー機能を利用できる方法をご紹介。下記は、解説サイトから引用していますが、分かりやすい関係図です。
Pythonデータ分析のためのDuckDB(組み込み用途のOLAP系のRDBMS)
duckdbを知るには、本家サイトの解説が詳しい。英文だがWebのページ翻訳利用できるので、日本語でも読める。
日本語での解説サイトは、こちらが解りやすい。いろいろ探してduckdbにたどり着いたと。
https://zenn.dev/kyami/articles/0189f25846bbba
コード例
分析するエクセルファイル内容 test.xlsx / sheet = 'test_data' AA BB CC 2 20 200 3 30 300 1 10 100 Pythonを統合環境IDLEで立ち上げ、pythonのプログラムファイル test.py(text file)作成し下記を書き込む 以下code内容 #---------------------------------------------------- import polars as pl import pandas as pd import duckdb filepath = "c:/test/test.xlsx" #エクセルファイル sheet = "test_data" #エクセルのシート名 #polarsでエクセルを読み込む pl_data = pl.read_excel( source = filepath, sheet_name = sheet, ) print(pl_data, columns) # ['AA', 'BB', 'CC'] クエリー作成に利用 #-----pl_data をtebleとし、部分を抽出するクエリー(文字列)を作成、 複数選択項目は区切り文字「,」を使用、終了は 「;」 #-----複数行の場合は、前後を 「"""」で囲むと見やすくできる q = """ select AA, BB from pl_data group by AA, BB order by AA ; """ #----------------------------- pl_data2 = duckdb.sql(q).pl() #クエリー結果をplのDataFrame へ print(pl_data2) AA BB 1 10 2 20 3 30 #---------- 選択した項目だけになり、データの大きさ順にソートされています。
上記のコードで、エクセルの特定のシートのデータをpolarsのデータファイルに読み込み、
分析に用いる項目名一覧をプリントし、
それをduckdbのtableとして利用し、sqlで必要な項目名を選択抽出し、
データを特定の項目で並び替えています。
エクセルの部分集合を容易に作成することができます。
作った部分集合をpolarsのデータファイルに読み込むことで、
独立したファイル(テーブル)として再利用もできます。
また、polarsの行選択(filter)やduckdbの行選択(where, having)を利用できます。
また、別の表とキー項目でリンクして、リレーショナルに分析することもできます。
鋳造ならば、製品マスターの単重と製造数実績を共通する品種コードでリンクして、単重x生産数=重量 の項目を作り、それを集計することで、特定品の生産量を出すことも容易です。
リレーショナルに利用するには、2つのファイルをキー項目一致でつなぎ合わせます。
SQL素人でも分かるテーブル結合(inner joinとouter join) が解りやすい。他にも解説は多数あります。研究してみてください。
これを使うことで、生産管理システムや、品質管理システムのデータを自分で分析ができるようになります。
元のエクセルファイルはそのままで、いろいろな分析が高速でできるって、ありがたいですね。
