NDLOCR-Lite をWebブラウザに移植した「NDLOCR-Lite Web」を公開
利用方法
上記サイト表示 → PDF・JPEGなど画像ファイル・TIFFをドロップかCtrl+Vで貼り付け → 変換
OCR結果は、右欄に表示される。コピーかDownloadする。
国立国会図書館が、所蔵する大量のPDF文書から文字抽出できるWebアプリを提供開始。
テストした結果、連続した数字0などを取りこぼすことがあります。
利用には、結果の確認が必要ですが、多くのページをもつPDFからOCRしてくれるフリーアプリが少ない中では貴重です。
ブラウザ上で画像やPDFのOCR処理ができます。
Webアプリではありますがローカルで処理が完結するので、画像や認識テキストが外部に送信されることはありません
Windows標準添付のSnipping Tool と同様のOCRですが、PDFなど多ページのものでも、一括してOCRで文字抽出ができます。
なお、パソコンインストール版では PDFのページごとにテキストファイルを連番名で作成するので、文書化には集約する機能が必要となります。
複数テキストファイルを一つにまとめる方法には、
・アプリを使う、
・エクセルなどのマクロなどを利用
・Pythonのプログラムで行う(下にプログラム例あり)
・Windows コマンド Dosでフォルダー内のテキストファイルを結合したファイルを作る
copy *.txt combined.txt
・Geminiに命令する(数ファイルなら簡単)
その他いろいろあり。
アプリの紹介記事紹介(X投稿)
アプリの紹介記事 国立国会図書館サイト
https://lab.ndl.go.jp/news/2025/2026-02-24/
2026年02月24日
NDLOCR-Liteの公開(パソコン等インストール利用)
NDLラボ公式GitHub(外部サイト)から、NDLOCR-Liteを公開しました。
NDLOCR-Liteは、NDLOCRの軽量版を目指して開発したOCRであり、ノートパソコン等の一般的な家庭用コンピュータやOS環境で、図書や雑誌といった資料のデジタル化画像からテキストデータが作成できるOCRです。
GPU(Graphics Processing Unit。画像描画等の高度な並列計算を処理する装置。)を必要とせず、軽量なOCR処理が可能です。
また、NDLOCRが不得意としていた英文や手書き文字等についても実験的に対応しています。
利用実例映像が下記
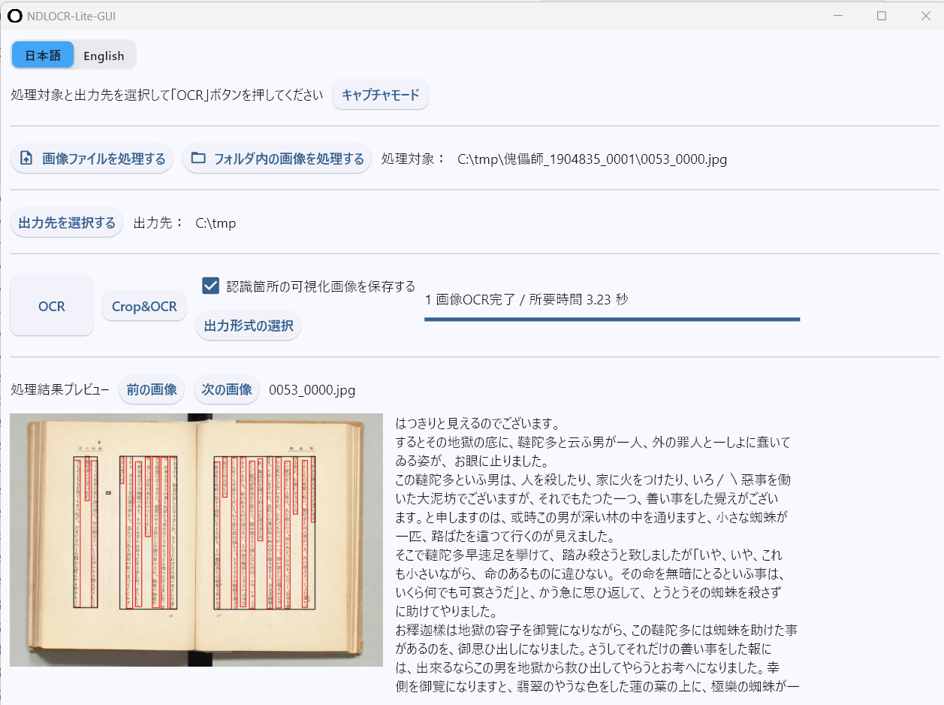
画像の出典:芥川竜之介 著『傀儡師』,新潮社,1919. 国立国会図書館デジタルコレクション https://dl.ndl.go.jp/pid/1904835/1/53 (参照 2026-02-18)
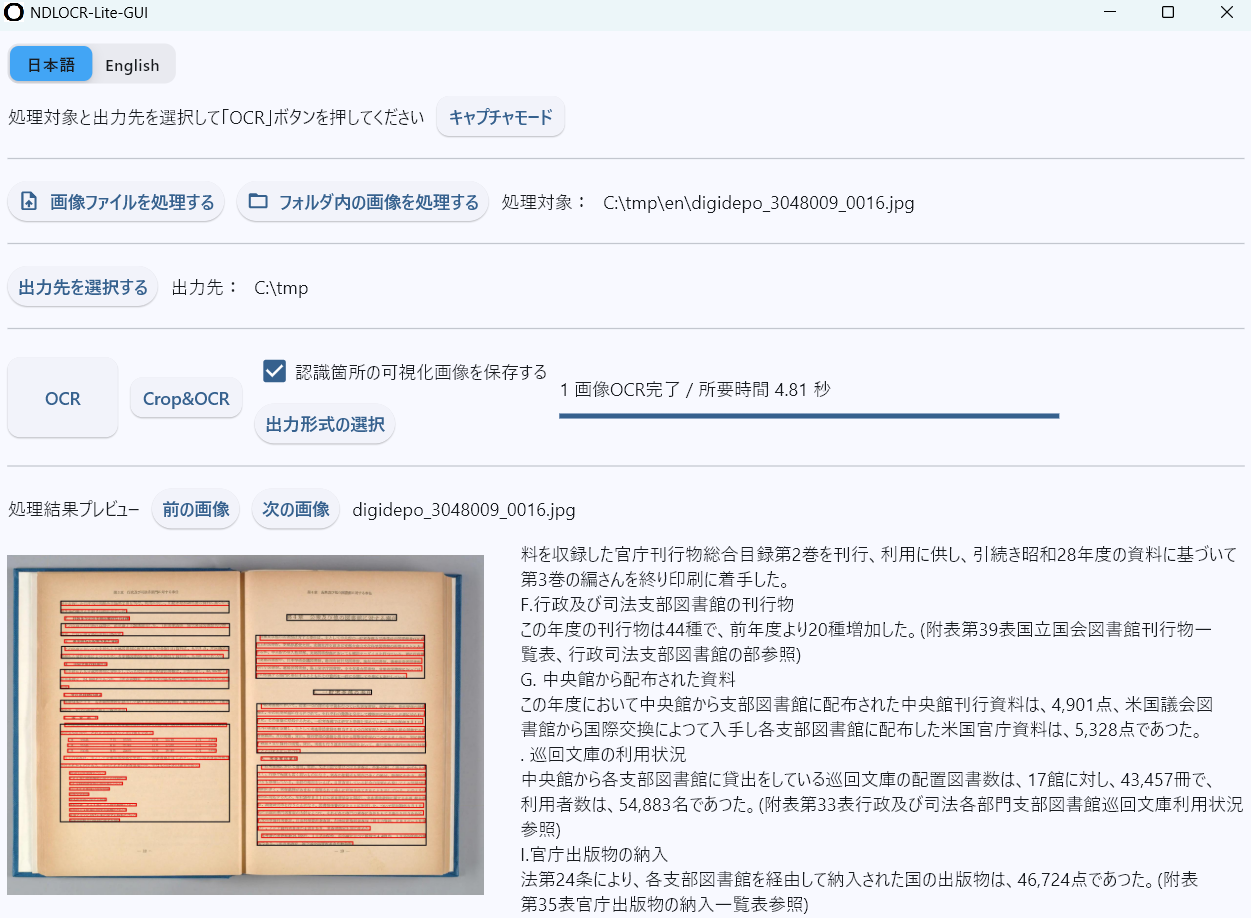
画像の出典:国立国会図書館総務部総務課 編『国立国会図書館年報』昭和29年度,国立国会図書館,1955. 国立国会図書館デジタルコレクション https://dl.ndl.go.jp/pid/3048009/1/16 (参照 2026-02-18)
NDLOCR-Lite
- GitHubリポジトリ(https://github.com/ndl-lab/ndlocr-lite )
これまで国立国会図書館が公開していたNDLOCR(外部サイト)では、実行環境にGPUを必須としていましたが、「NDLOCR-Lite」ではGPUは不要となっています。
あわせて、デスクトップアプリケーションを用意しているため、マウス操作のみで簡単にお使いいただけます。
Windows(Windows 11)、Mac(macOS Sequoia)及びLinux(Ubuntu 22.04)の各OS環境において動作を確認しています。
次のURLからご利用のOSに合わせた最新版をダウンロードしてお使いください。
https://github.com/ndl-lab/ndlocr-lite/releases
使い方については次のページをご覧ください。
NDLOCR-Liteは、国立国会図書館がCC BY 4.0ライセンスで公開しています。詳細はGitHubのREADMEをご参照ください。
なお、これまで提供していたGPUを必要とするNDLOCRについても、引き続き同リポジトリ(https://github.com/ndl-lab/ndlocr_cli )からご利用いただけます。
Web上で完結し、資料はPC内で完結するそうで、PDFなら何でも処理できるそうです。
画面の文字をOCR処理するWindows11の標準アプリもありますが、PDF文書全体を処理するのは大変です。
このアプリなら、文書全体のテキストを抽出できるので、テストする意味があります。
紹介するXの投稿をご紹介します。
また、Python利用したアプリも提供されています。これは1G程度のメモリーがあれば軽く動作するそうです。
テストしたところ、ページごとのテキストファイルを作成してくれます。
Python で、全てのテキストファイルを読み込んで、一つのテキストファイルにしてくれるアプリをGeminiが作ってくれました。
一つのディレクトリに入れたものをまとめてそのディレクトリに作ってくれる。
Python program PDFのページ単位で作成されたテキストファイルを結合して一つにするPython プログラム例です(Gemini作成、動作確認済み)
対象ファイルを入れて作業するディレクトリを指定することもできます。
import globfiles = glob.glob(“*.txt”) # フォルダ内の全txtファイルを取得with open(“combined.txt”, “w”, encoding=”utf-8″) as outfile:for f in files:with open(f, “r”, encoding=”utf-8″) as infile:outfile.write(infile.read() + “\n\n”) # ファイル間に改行を入れて結合
